На образовательной платформе «Skillbox» с 14 по 16 ноября прошли конференции по Искусственному интеллекту.
Работа в области распознавания и синтеза речи сегодня одна из наиболее востребованных областей обучения искусственного интеллекта. Развитие технологий отражает прогресс в области обработки и анализа больших объемов аудиоданных в алгоритмах машинного обучения.
О синтезе и распознавании речи рассказал Иван Дулов — руководитель платформы «Audiogram» MTS AI. Спикер начал выступление с говорящей машины Фабера, созданной в 1791 году. Эта машина оперировала воздушными струями, направляемыми на металлический язычок, а человек помогал аппарату генерировать звуки с помощью ладони. Устройство произносило слова на подобии: «мама», «папа».

В 1938 году появилась машина Voder, разработанная компанией Bell Labs. Она служила генератором звуковых частот, которая напоминала отдаленное сходство с речью человека. Человек изменял интонацию с помощью педалей. Также спикер рассказал об экспериментальном устройстве — машина IBM Shoebox, которая распознавала 16 слов, включая цифры и команды для арифметических операций. Shoebox использовала микрофон для распознавания речи и передавала команды на счетное устройство, которое печатало арифметические результаты на бумаге.

В 1980 году появилась машина IBM Tangora, основанная на статистическом алгоритме скрытых моделей Маркова. Точность распознавания речи в Tangora не превышала 80%. Этот компьютерный алгоритм производит расчет вероятностей того, что слышимый звук является частью конкретного слова. Изобретение помогало расширенить словарный запас: Tangora распознавала 20 тысяч слов и пару предложений.

Как работает синтез речи?
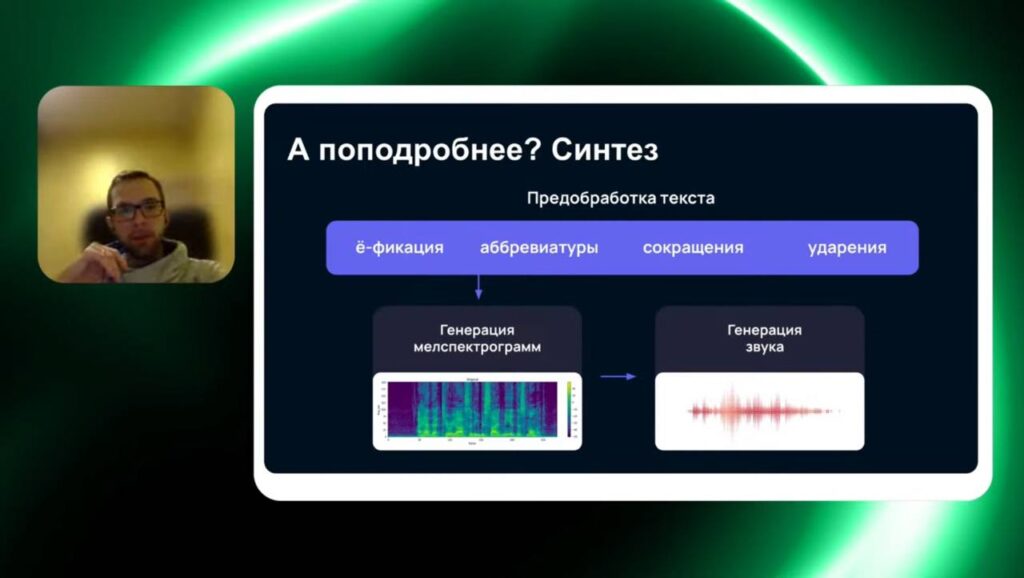
Далее Иван рассказал, как работает синтез речи на основе искусственного интеллекта и параметрического метода. На первом этапе происходит предобработка текста: раскрытие аббревиатур, сокращений и ударений. Затем происходит формирование спектрограммы — визуального представления аудиосигнала по частотам и времени. Эта спектрограмма затем преобразуется через вокодер, который отвечает за преобразование спектральных данных в готовую звуковую волну.
Использование акустической модели и искусственного интеллекта в синтезе разрешает достичь близкого к голосу человека результата. Благодаря этим технологиям синтез речи становится реалистичным и естественным. Сегодня синтез речи используется в сферах: от голосовых помощников, таких как Алиса, Сири, Алекса, до систем автоматизации в колл-центрах и банках. Для создания большей правдоподобности, звуковая волна обрабатывается с добавлением фоновых шумов, чтобы голос ассистента звучал ближе к реальному голосу человека.
Синтез речи основан на обучении, который включает сбор дата-сета и использование этого набора данных для обучения модели. Чем больше данных доступно, тем лучше будет качество синтеза. Для создания модели синтеза речи также требуется запись голоса диктора в студии, работа занимает не менее 20 часов. После этого материалы проходят ряд этапов обработки, включая разметку, предобработку и преобразование звуковых волн в спектрограммы. Затем тренируется акустическая модель, которая основана на искусственном интеллекте. Эта модель преобразует звук в фонемы, а затем языковая модель использует словарь, чтобы сопоставить звуки и буквы и выбрать наиболее подходящее слово.
Обучение распознавания речи также требует набора данных, состоящее из не менее 1000 часов записей звука. После этапов оттекстовки, разметки и предобработки аудиоданных происходит обучение нейросети модели распознавания.
Иван объяснил, что качество синтеза речи измеряется экспертной группой. Участники оценивают величину от 1 до 5 для каждого критерия, определенного в опорном листе. Оценка качества зависит от набора критериев, аудиофрагментов, предоставленных для оценки, и количества экспертов в группе. Некоторые критерии оценки качества включают задержку ответа системы синтеза и значение показателя SPS, который определяет, сколько секунд речи синтезируется за одну секунду.
Как работает распознание речи?
Распознавание речи – это не только способ преобразовать звуковые волны в текст, но и инструмент, который обладает рядом дополнительных функций. Одной из таких функций является пунктуация и капитализация. Распознавание речи способно определить места, где ставятся знаки препинания, и определить, какие слова пишутся с заглавной буквы.Также важно распознавание эмоций. Системы распознавания речи обнаруживают интонацию и интонационные модификации, чтобы определить эмоциональное состояние говорящего. Распознавание речи также способно определить пол и возраст. На основе анализа шаблонов и интонации голоса системы предполагают возраст и пол человека, что будет полезным при создании персональных систем или в маркетинговых исследованиях. Также Иван объяснил, что диаризация — это разделение спикеров, которые говорят в одном канале. Это помогает идентифицировать, кто говорил, и анализировать речь отдельных участников или групп, что полезно в многих областях, включая транскрипцию интервью и работы с участниками конференций.
Спикер рассказал, что одним из аспектов распознавания речи — способность работать в мультиязычной сфере. Системы распознавания речи обучены распознавать и анализировать речь на разных языках. Это означает, что обрабатываются аудио сигналы, содержащие смесь языков, и предоставляют точный текстовый вывод для каждого используемого языка.